Improving Effectiveness of Knowledge Graph Generation Rule Creation and Execution
Chapter 1: Introduction
More and more data is generated by an increasing number of agents (applications and devices) that are connected to the Internet. For example, Twitter users wrote 473,400 tweets per minute in 2018, compared to 100,000 in 2013, and Instagram users posted 46,740 photos per minute in 2018, compared to 3,600 in 2013. At the same time, there were 15,41 billion Internet connected devices installed in 2015, while it is expected that by 2025 there will be 75,44 billion installed. They all contribute to data that is available on the Web.
When this data is analyzed, combined, and shared powerful, new techniques can be designed and deployed, such as artificial intelligence applied by personal assistants (e.g., Apple's Siri and Amazon's Alexa), improved search engines (e.g., Google Search and Microsoft's Bing), and decentralized data storages (as opposed to a large, central storage used by big companies).
Due to this increase in data, the representations originally used for data, such as simple JSON and XML documents, have become insufficient. They make it hard for agents to exchange and reuse data, residing in different data sources, on the Web, because arbitrary structures can be added to the representations without saying what these structures actually mean. Thus, the problem is how can we represent data on the Web that makes it possible for agents to exchange this data with other agents and reuse it for their own purposes?
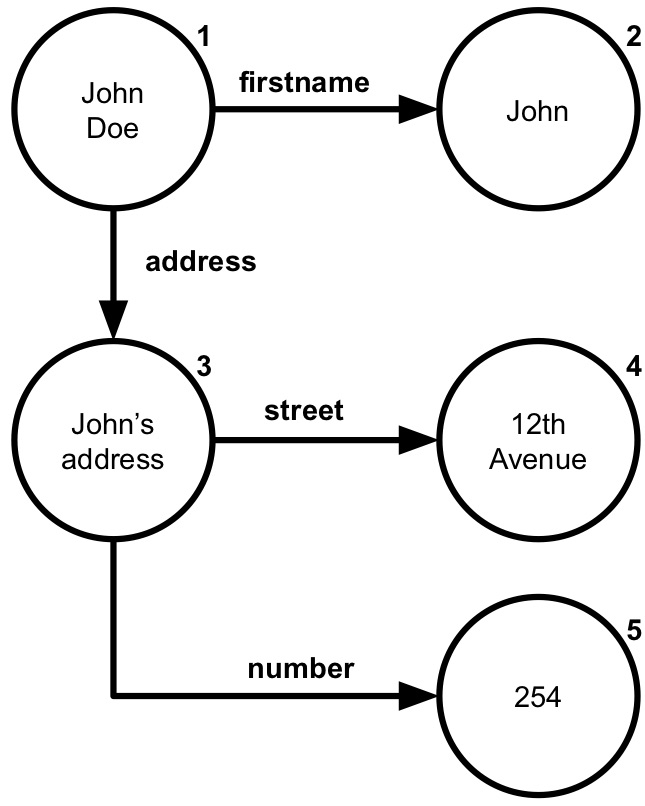
Figure 1.1: Knowledge graph about John Doe with his name and address. Nodes represent entities and arrows represent directed relationships.
The Semantic Web offers a solution to this problem: it is an extension of the World Wide Web that allows data to be exchanged between multiple agents that generate and use data in different ways on a large scale, such as the Web. Semantics is concerned with relationships between entities (something that exists apart from other things) and what they mean in reality. The Semantic Web adds semantics to the Web through a set of formats and technologies that provide a formal description of concepts and relationships within a given domain. The main technology is knowledge graphs: directed graphs that provide semantic descriptions of entities and their relationships. For example, in Figure 1.1 a knowledge graph describes John Doe and his address. The nodes represent entities and arrows directed relationships. John Doe's first name is "John" (an arrow from node 1 to 2) and his address (arrow from node 1 to 3) has street "12th Avenue" (arrow from node 3 to 4) and number "254" (arrow from node 3 to 5).
Knowledge graphs are often generated from other data sources, such as multiple databases and files that each represent their data in different ways. For instance, the DBpedia knowledge graph is generated from Wikipedia; the Google knowledge graph is generated from different sources, including data coming from Google's own services and Wikipedia; and IBM's Watson Discovery Knowledge Graph is generated from custom data sources. The DBpedia knowledge graph is generated by extracting the relevant data from the Wikipedia pages and assigning the corresponding concepts and relationships. A custom Watson Discovery Knowledge Graph can be generated by extracting unstructured text from documents, classifying and tagging the text, correlate it with other text, filter the results, and representing the results as a knowledge graph.
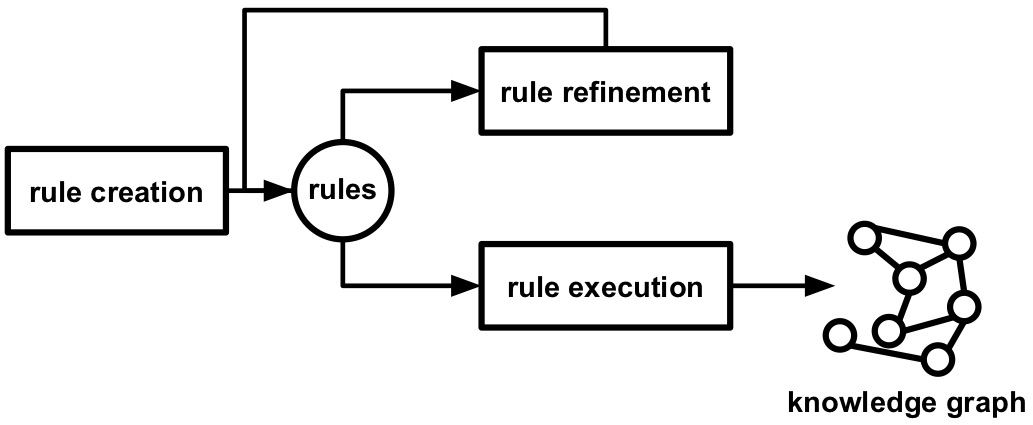
Figure 1.2: Rules are created, refined if needed, after which they are executed to generate a knowledge graph.
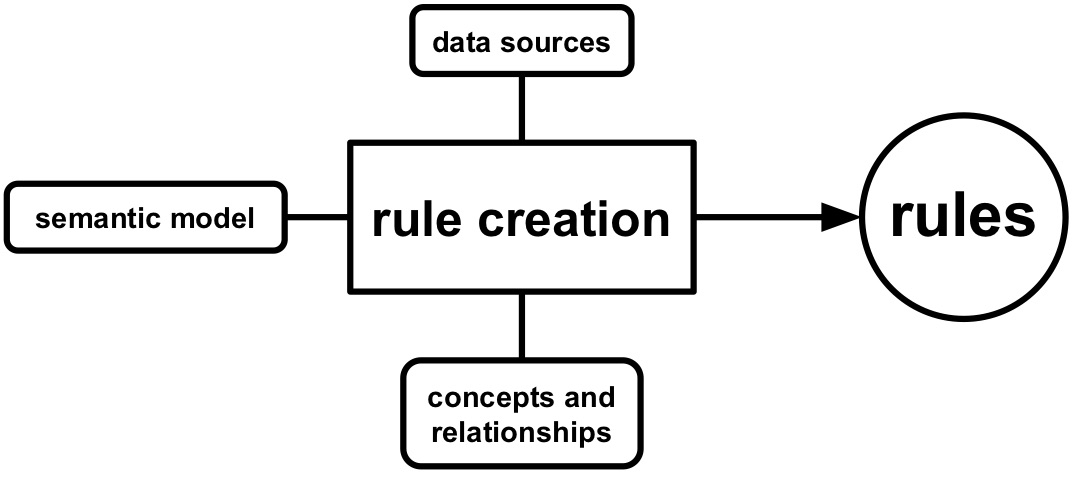
Figure 1.3: Rules are influenced by data in data sources, concepts, relationships, and semantic model.
A common way to generate these knowledge graphs is by using rules, which are created, refined, and executed (see Figure 1.2). The rules attach semantic annotations to data in those sources. Semantic annotations provide additional information about various entities that are described in the data source (e.g., things, people, companies, and so on). The semantic annotations are added using machine-understandable concepts and relationships, which allow agents to share information in a domain. For example in the domain of families, concepts include child, mother, and brother, and relationships include "is sibling of" and "is parent of". Which concepts and relationships are used and how they are applied to data sources is contained in a semantic model. Rules thereby determine how data sources are modeled using specific concepts and relationships during knowledge graph generation. The syntax and grammar of these rules are determined by a knowledge graph generation language, such as R2RML and RML. For example, a language can say that if there are rules that describe how a relationship between two entities is generated then there also need to be rules that describe how these entities are generated. Thus, the rule creation is influenced by three aspects (see Figure 1.3):
- data sources,
- concepts and relationships, and
- semantic model.
In most cases rules are created manually by users, optionally assisted by semi-automatic approaches.
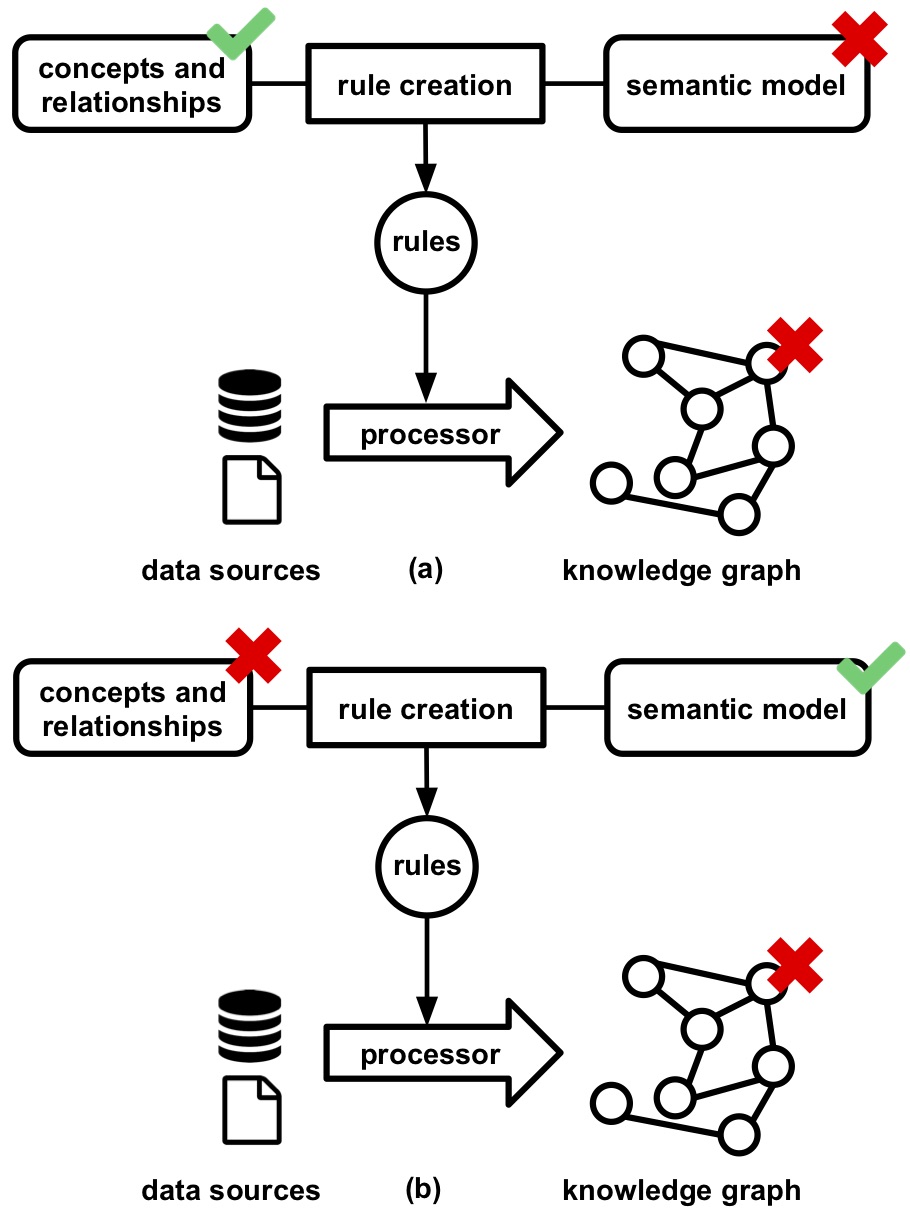
Figure 1.4: Knowledge graphs contain inconsistencies if they are introduced by the concepts, relationships, or semantic model during the rule creation.
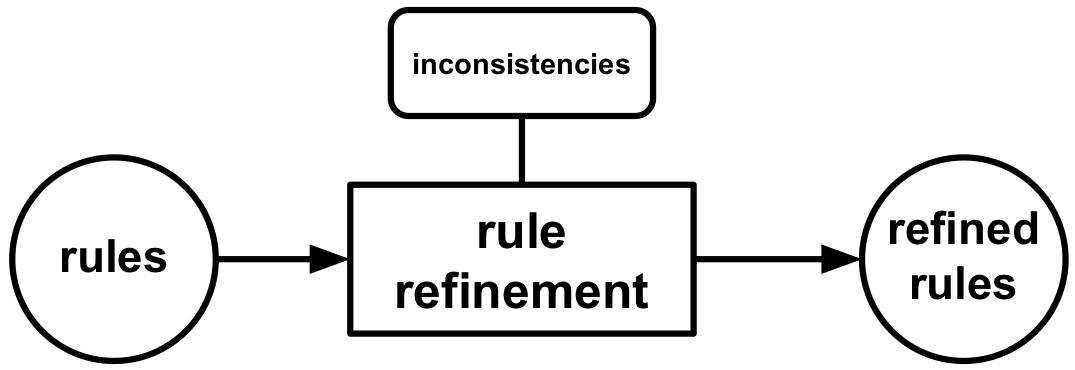
Figure 1.5: Rule refinement takes a set of existing rules as input, is influenced by inconsistencies, and outputs a set of refined rules.
Once (a subset of) the rules are created, they are refined to resolve inconsistencies, if there are any. Inconsistencies in knowledge graphs are introduced when concepts and relationships are used without adhering to their restrictions, and this affects the graphs' quality. For example, a person cannot be a sibling and a parent of another person at the same time. Possible root causes for these inconsistencies include:
-
semantic model that introduce new inconsistencies by, for example, not using the suitable concepts and relationships as mentioned here and here (see Figure 1.4a); and
-
concept and relationship definitions that do not model the domain as desired (see Figure 1.4b).
For example for the former, if a rule defines that all persons in a certain data source are both brothers and sisters then inconsistencies are introduced because a person is either a brother or a sister of someone, but never both. For the latter, if it is defined that if a person is someone's sister it is also that person's mother inconsistencies are introduced because if a person is someone's sister then it cannot be that person's mother at the same time and vice versa. Thus, rule refinement takes a set of existing rules as input, is influenced by inconsistencies, and outputs a set of refined rules (see Figure 1.5).
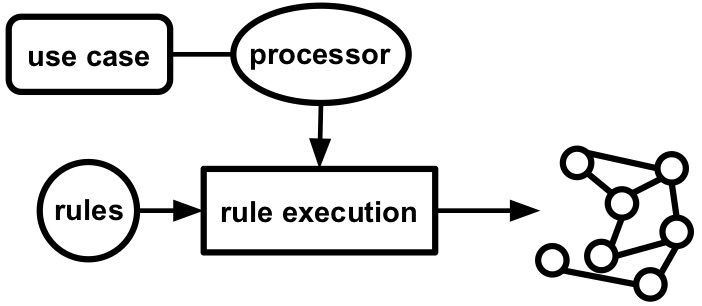
Figure 1.6: During rule execution a processor, selected based on the use case, execute the rules to generate the corresponding knowledge graph.
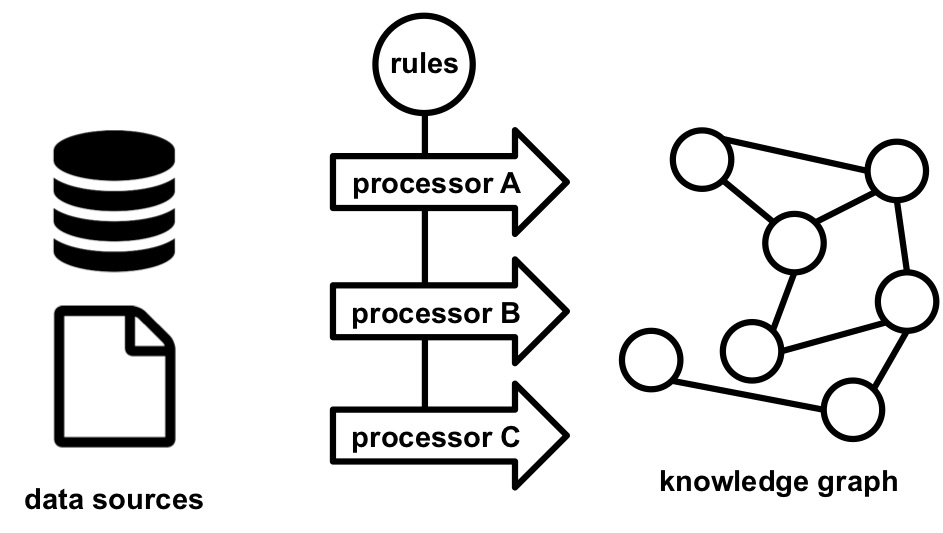
Figure 1.7: Different processors can be used for the execution of rules, without requiring changes to rules.
Once the rules are created and refined, they are executed to generate a knowledge graph. This is done via a processor: a software tool that, given a set of rules and data sources, generates knowledge graphs (see Figure 1.6). Multiple processors can be developed for a single knowledge graph generation language while each processor has a different set of features: conformance to the specification of the rule language, API, programming language, scalability, and so on. Users can switch between them without changing the rules (see Figure 1.7), and thus, the selection of the most suitable processor depends on the use case at hand (see Figure 1.6). For example, when a processor wants to be integrated in existing software as a library, then a processor's programming language and API affect whether this is possible or not. When a processor is needed to deal with huge amounts of data, then a processor's scalability determines if it can be used or not.
1.1 Research challenges
In this dissertation, we look at three research challenges of knowledge graph generation using rules: the first one deals with rule creation, the second one with rule refinement, and the third one with rule execution. Rule creation is influenced by users' understanding of the different components used during the creation: data sources, rules, concepts, relationships, and semantical model. This leads to the first challenge:
Challenge 1: Improvement of users' understanding of the rule creation's components.
Possible root causes for inconsistencies in knowledge graphs are the semantic model and the definitions of the concepts and relationship. These inconsistencies need to be removed, during rule refinement, or are ideally avoided in the first place. This leads to the following challenge:
Challenge 2: Avoidance and removal of inconsistencies introduced by concepts, relationships, and semantic model.
During rule execution a processor is used to generate knowledge graphs.
If multiple processors are available,
users need to select the most suitable one for the use case at hand.
However, this is not trivial if each processor has a different set of features.
This leads to the following challenge:
Challenge 3: Selection of the most suitable processor for the use case at hand.
1.2 Background
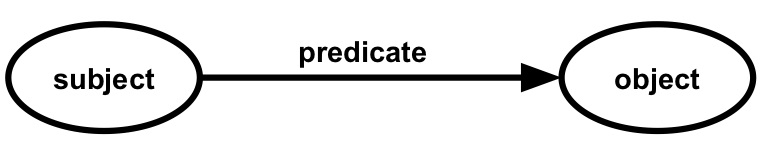
Figure 1.8: Each RDF triple consists of a subject, predicate, and object.
Knowledge graphs can be materialized using the Resource Description Framework (RDF). It is a framework for representing information on the Web using a directed graph-based model. A graph consists of zero or more triples and each triple consists of a subject, predicate, and object (see Figure 1.8). For example, when aligning with a natural language, the sentence "John has age 30" can be seen as a triple, where "John" is the subject, "has age" is the predicate, and "30" is the object.
In RDF, a subject is identified by an Internationalized Resource Identifier (IRI) or blank node; a predicate an IRI; and an object an IRI, blank node or literal. IRIs and literals are used for entities and denote something in this world, including physical things, documents, abstract concepts, numbers, and text. The IRI is an internet protocol standard which uses a series of characters that unambiguously identifies a particular resource, typically on the Web. Examples are https://google.com/ and https://www.wikipedia.org/. Literals are also a series of characters, but they are used for values such as strings, numbers, and dates. Examples are "John", "30", and "2019-05-21". Furthermore, they have datatypes or are language-tagged. Datatypes, which are also IRIs, define the possible values of a literal, such as numbers and dates. For example, a literal that represents the age of a person will have "number" as datatype and a literal that represents the birth date of a person will have "date" as datatype. Language-tagged literals denote a text in a human language. For example, "12th Avenue" denotes a street name in English. Blank nodes are used for entities for which no explicit identifier is required, opposed to IRIs.
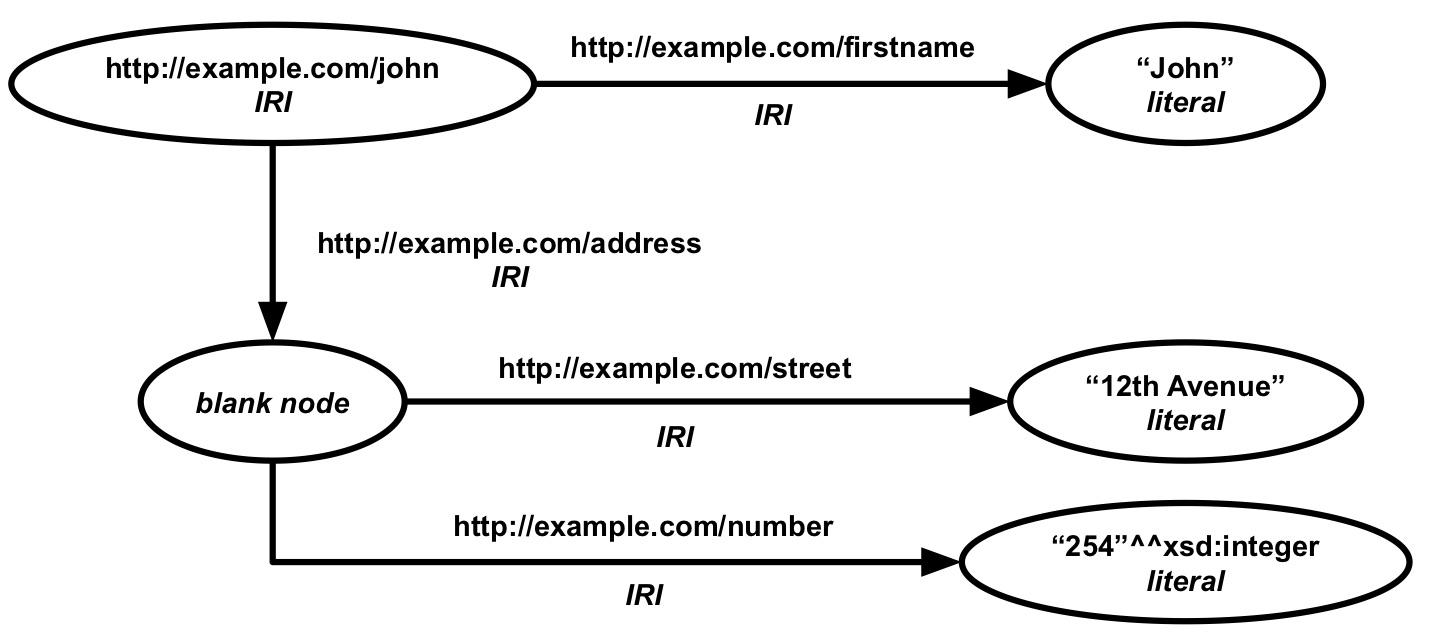
Figure 1.9: An RDF graph describing a person called John and his address.
An ontology includes machine-understandable definitions of basic concepts in the domain and relationships among them and encodes the implicit rules constraining the structure of a piece of reality. Such implicit rules can be encoded as ontological axioms in OWL and are henceforth referred to as restrictions. For example, the domains and ranges of properties are restricted to a set of classes. Such restrictions are either defined via the ontology term's definitions (e.g., a "Person" is a concept and "is sibling of" a relationship) or via the interpretation of the ontology's axioms (e.g., a person is either a brother or a sister of someone, but never both) as restrictions as done here and here.
In Figure 1.9, an example can be found of how RDF and ontologies are used to describe John Doe and his address. An IRI is used for the entity that represents John Doe (http://example.com/john). A literal is used for his name and is related to John Doe via an IRI (http://example.com/firstname). A blank node is used for the entity that represents John Doe's address and is related to John Doe via an IRI (http://example.com/address). Literals are used for the address' street and number. For the latter, a datatype (http://example.com/integer) is used to make clear that the number only contains digits and is not, for example, a date.
A number of knowledge graph generation languages have been proposed, such as the RDB to RDF Mapping Language (R2RML) and the RDF Mapping Language (RML). R2RML is a W3C recommendation that focuses on the generation of knowledge graphs from relational databases (RDBs). RML is an extension of R2RML and supports multiple, different data sources, such as databases, files, and Web APIs, and data formats, such as CSV, JSON, and XML. However, manually creating rules requires a substantial amount of human effort. Therefore, a significant number of tools with a graphical user interface (GUI), henceforth referred to as rule editors, were implemented to help users to create rules as described here, here, and here. They offer different features, which are not necessarily found in one single editor. For example, they hide the syntax and grammar of the underlying language, they visualize the generated knowledge graph, they allow to view the data sources, and they support data sources with different data formats.
Different processors have been developed for the existing knowledge graph generation languages, such as the RMLMapper, CARML, Morph-RDB, and R2RML Parser. The conformance of these processors to the language's specification is assessed based on whether the correct knowledge graph is generated for a set of rules and certain data source or not. Consequently, users are able to consider the processors' conformance to the specification, among other features, during their selection of the most appropriate processor for a certain use case. For example, do users want a processor that supports the complete specification, or do they prefer a processor that does not support certain aspects of the specification, but executes the rules faster?
1.3 Research questions and hypotheses
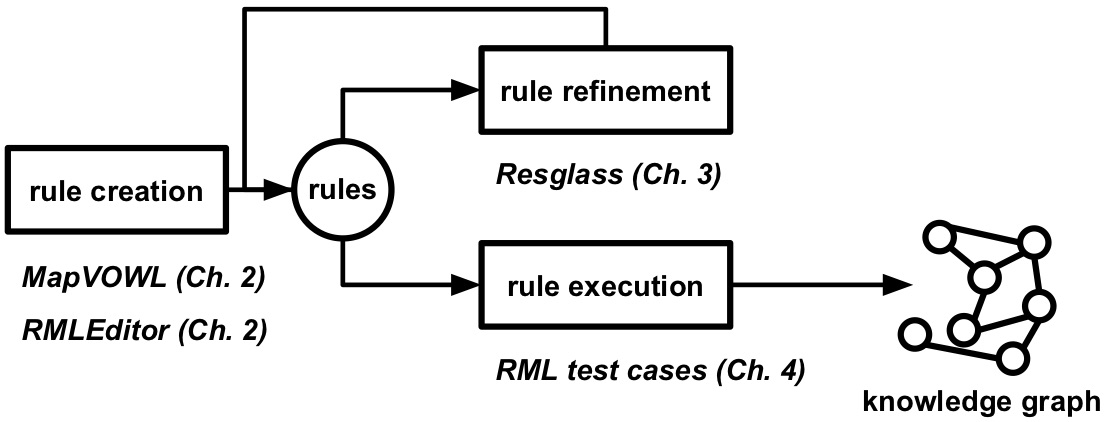
Figure 1.10: MapVOWL and the RMLEditor contribute to rule creation (Chapter 2), Resglass to rule refinement (Chapter 3), and the RML test cases to rule execution (Chapter 4).
In this section, we identify the research questions and hypotheses identified through the research challenges and existing work, and highlight the corresponding solutions developed during my PhD. Each solution either contributes to rule creation, rule refinement, or rule execution (see Figure 1.10).
Existing rule editors, such as RMLx and Map-On, facilitate the creation of rules and thus, contribute to tackling Challenge 1 and 2. However, the design of these tools and their GUIs are not thoroughly investigated yet. This leads to the following two research questions:
Research Question 1: How can we design visualizations that improve the cognitive effectiveness of visual representations of knowledge graph generation rules?
Research Question 2: How can we visualize the components of a knowledge graph generation process to improve its cognitive effectiveness?
Note that cognitive effectiveness is defined as the speed, ease, and accuracy with which a representation can be processed by the human mind. To address the first question, we introduce a visual notation for knowledge graph generation rules called MapVOWL. This leads to the following hypothesis:
Hypothesis 1: MapVOWL improves the cognitive effectiveness of the generation rule visual representation to generate knowledge graphs compared to using RML directly.
RML was chosen over other existing knowledge graph generation languages as it supports rules with data from multiple, heterogeneous data sources. To address the second question, we developed a graph-based rule editor called the RMLEditor. This leads to the following hypothesis:
Hypothesis 2: The cognitive effectiveness provided by the RMLEditor's GUI improves the user's performance during the knowledge graph generation process compared to RMLx.
RMLx was chosen over other existing rule editors as it allows to annotate multiple, heterogeneous data sources and values. More, it also uses graph visualizations to represent the rules; however a form-based approach is used to edit the rules. Both MapVOWL and the RMLEditor contribute to rule creation (see Figure 1.10). They have been used by partners and different projects including COMBUST and the Belgian Chapter of Open Knowledge Foundation.
In previous research efforts, a method to resolve inconsistencies by automatically refining the corresponding rules has been developed, tackling Challenge 2. However, this method assumes that ontologies do not contain inconsistencies. Furthermore, when a high number of rules are involved in inconsistencies users have no insights regarding the order in which rules should be inspected. This issue leads to the following research question:
Research Question 3: How can we score and rank rules and ontology terms for inspection to improve the manual resolution of inconsistencies?
To address this question, we developed a new method called Resglass that extends the existing rule-driven method. The rules and ontology terms are automatically ranked in order of inspection based on a score that considers the number of inconsistencies a rule or ontology term is involved in. This leads to the following hypothesis:
Hypothesis 3: The automatic inconsistency-driven ranking of Resglass improves, compared to a random ranking, by at least 20% the overlap with experts' manual ranking.
A number of knowledge graph generation rule languages, such as RML, support multiple, heterogeneous data sources, instead of only supporting a single data source or data format, such as R2RML. However, for these languages no test cases are available that allow to determine the conformance of corresponding processors to the languages' specifications. This makes it hard for users to determine the most suitable processor for a certain use case. Furthermore, it has not been investigated yet what the characteristics are of such test cases and how they differ from test cases only focusing on a single data source or data format. This leads to the following research question, tackling Challenge 3:
Research Question 4: What are the characteristics of test cases for processors that generate knowledge graphs from heterogeneous data sources independent of languages' specifications?
To address this question, we designed an initial set of conformance test cases for RML, based on the R2RML test cases. We use RML, because it supports heterogeneous data sources and is based on R2RML for which already test cases are designed. This is done towards designing test cases that are independent of RML and are applicable to all languages that generate knowledge graphs from heterogeneous data sources.
1.4 Publications
The work presented in this dissertation is based on four peer-reviewed publications in international, scientific journals and conference proceedings:
- RMLEditor: A Graph-Based Mapping Editor for Linked Data Mappings
- Specification and Implementation of Mapping Rule Visualization and Editing: MapVOWL and the RMLEditor
- Rule-driven inconsistency resolution for knowledge graph generation rules
- Conformance Test Cases for the RDF Mapping Language (RML)
The following lists provide an overview of all publications I (co-)authored during my PhD.
1.4.1 Publications in international journals
- Specification and Implementation of Mapping Rule Visualization and Editing: MapVOWL and the RMLEditor
- Rule-driven inconsistency resolution for knowledge graph generation rules
1.4.2 Publications in international conference proceedings
- Merging and Enriching DCAT Feeds to Improve Discoverability of Datasets
- Using EPUB 3 and the Open Web Platform for Enhanced Presentation and Machine-Understandable Metadata for Digital Comics
- Linked Data-enabled Gamification in EPUB 3 for Educational Digital Textbooks
- Towards Approaches for Generating RDF Mapping Definitions
- Towards a Uniform User Interface for Editing Mapping Definitions
- Semantically Annotating CEUR-WS Workshop Proceedings with RML
- RMLEditor: A Graph-Based Mapping Editor for Linked Data Mappings
- Graph-Based Editing of Linked Data Mappings using the RMLEditor
- Linked Sensor Data Generation using Queryable RML Mappings
- Querying Dynamic Datasources with Continuously Mapped Sensor Data
- Towards an Interface for User-Friendly Linked Data Generation Administration
- Data Analysis of Hierarchical Data for RDF Term Identification
- Modeling, Generating, and Publishing Knowledge as Linked Data
- Ontology-Based Data Access Mapping Generation using Data, Schema, Query, and Mapping Knowledge
- Semi-Automatic Example-Driven Linked Data Mapping Creation
- Representing Dockerfiles in RDF
- What Factors Influence the Design of a Linked Data Generation Algorithm?
- Declarative Rules for Linked Data Generation at your Fingertips!
- Automated extraction of rules and knowledge from risk analyses: a ventilation unit demo
- Towards Adaptive Anomaly Detection and Root Cause Analysis by Automated Extraction of Knowledge from Risk Analyses
- Towards a Uniform User Interface for Editing Data Shapes
- Knowledge Representation as Linked Data
- Mapping languages analysis of comparative characteristics
- SAD Generator: eating our own dog food to generate KGs and websites for academic events
- Conformance Test Cases for the RDF Mapping Language (RML)
1.5 Outline
The remainder of the dissertation consists of three chapters that are based on the four peer-reviewed publications that contribute to my PhD, and a conclusion chapter. In Chapter 2, we focus on rule creation and address Research Questions 1 and 2. More specific, we discuss the initial version of the RMLEditor: our software tool to create rules using graph-based visualizations; followed by MapVOWL: our visual notation for knowledge graph generation rules; and the updated version of the RMLEditor. In Chapter 3, we focus on rule refinement and address Research Question 3. More specific, we describe Resglass: our rule-driven method for the resolution of inconsistencies in ontologies and rules. In Chapter , we focus on rule execution and address Research Question 4. More specific, we elaborate on our initial set of conformance test cases for RML as exploratory step towards designing language-independent test cases for knowledge graph generation. In Chapter 5, we conclude the work of this dissertation and discuss future research options.
----