Getting started with Walder
2020-08-31
Walder offers an easy way to set up a website or Web API on top of decentralized knowledge graphs. Knowledge graphs incorporate data together with the meaning of that data. This makes it possible to combine data from multiple knowledge graphs, even if different, independent parties maintain or host them. Knowledge graphs can be hosted via Solid PODs, SPARQL endpoints, Triple Pattern Fragments interfaces, RDF files, and so on. Using content negotiation, Walder makes the data in these knowledge graphs available to clients via HTML, RDF, and JSON-LD. Users define in a configuration file which data Walder uses and how it processes this data. This tutorial introduces you to Walder.
Table of contents
- Before we start the tutorial
- Example
- How to start a configuration file
- How to add knowledge graphs
- How to add paths
- How to add views
- How to run Walder
- How to process query results
- How to add parameters to paths
- Bonus: content negotiation
- Wrapping up
- More information
1. Before we start the tutorial
1.1. Learning objective
At the end of the tutorial you will be able to set up a website on top of decentralized knowledge graphs by using Walder.
1.2. Prerequisites
We assume that you are familiar with
- knowledge graphs and more specific the Resource Description Framework (RDF)
- bash
- Node.js (v12 or higher) and npm
1.3. How to use the tutorial
There are two ways to complete this tutorial: you read the explanations and either
- read the examples, or
- try out the examples yourself using your computer.
You can find the files of this tutorial in this repository.
2. Example
For this tutorial we want to create a website that displays our ratings of the tv shows we watched. Our website is getting the required data from two knowledge graphs containing the following data:
- our tv show ratings
- details about these tv shows, such as title, release year and so on.
We will combine the data in both knowledge graphs to create these two Web pages:
- list of tv shows with their ratings at the path
/ratings - list of tv shows with "x"-star ratings at the path
/rating/{x}, where "x" is a value between 1 and 5.
3. How to start a configuration file
A configuration file for Walder is
a valid OpenAPI 3.0 file
with Walder-specific extensions.
These extensions start with x-walder- in the configuration file.
We do the following steps
- Create a config file called
config.yaml - Add the following content to the file:
openapi: 3.0.2
info:
title: 'Ratings website'
version: 1.0.0
copy successLet's have a look at this.
openapistates the OpenAPI version we are using.infocontains the title and version of our website.
4. How to add knowledge graphs
You add knowledge graphs, also called data sources, to Walder by listing them
under the section x-walder-datasources.
For the two aforementioned knowledge graphs this results in
x-walder-datasources:
- https://pieterheyvaert.com/data/example/walder/ratings.ttl # Turtle file
- https://data.betweenourworlds.org/latest # Triple Pattern Fragments server
copy successAdd this section to the root of config.yaml.
Although both data sources are hosted using different technologies, you do not need to specify these technologies as Walder determines the correct way to query a data source on the fly. If interested, you can open both data sources in your browser and explore them.
5. How to add paths
You add paths under the section paths,
which is defined in the OpenAPI specification.
The following is an entry for the path ratings:
paths:
/ratings:
get:
summary: Returns a list of all tv shows and their ratings.
responses:
200:
description: List of all tv shows and their ratings.
x-walder-input-text/html: ratings.handlebars
x-walder-query:
graphql-query: >
{
id @single
title @single
review @single {
rating @single {
value @single
}
}
}
json-ld-context: >
{
"schema": "http://schema.org/",
"review": "schema:review",
"rating": "schema:reviewRating",
"value": "schema:ratingValue",
"title": "schema:name"
}
copy successAdd this section to the root of config.yaml.
Let's have a closer look at this entry.
/ratingsis the path we want and is the section where we add the details about that path.getsays that for this path we want to support an HTTP GET and it is the section where we add the details about the GET.summarycontains a summary of the request.responsesis a section that contains all supported responses based on their HTTP status code.200is a section that contains all the information to handle a response with status code 200.descriptioncontains a description of the response.x-walder-input-text/htmlpoints to a template-engine file that renders an HTML file, which is send back to the client as response. Walder supports different template engines, such as Pug and Handlebars. In our example, we have a Handlebars file calledratings.handlebars(which we will create later).x-walder-queryis a section that contains information about query that is executed over the knowledge graphs. Walder gives the result of this query to the template engine, which uses this result during the rendering of the HTML file.graphql-querycontains the GraphQL-LD query that is executed over the knowledge graphs.json-ld-contextcontains the JSON-LD context that is needed for the GraphQL-LD query.
Let's have a closer look at the query and the context. The GraphQL-LD query is
{ id @single title @single review @single { rating @single { value @single } } }copy success
This query returns the URLs, titles, and reviews of the shows.
The variable id contains the URL.
The variable title is a string with the title.
The variable review is an object with a rating,
which is also an object having the variable value with the actual rating value.
We use @single to get strings and objects instead of arrays of strings and objects,
which is the default.
The query in itself is not enough, because these variables are not defined across all data sources. To tackle this, we use this JSON-LD context:
{ "schema": "http://schema.org/", "review": "schema:review", "rating": "schema:reviewRating", "value": "schema:ratingValue", "title": "schema:name" }copy success
The context defines the prefix for http://schema.org/ and
the URLs for all the variables.
For example, review has as URL http://schema.org/review.
6. How to add views
In our path entry,
we have x-walder-input-text/html: ratings.handlebars.
Walder will look for the file ratings.handlebars in the folder views
relative to the location of the config file.
We do the following steps:
- Create a folder
views. - Add a file
ratings.handlebarswith the following content:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
</head>
<body>
<h1>Ratings</h1>
<div>
<ul>
{{#each data}}
<li>{{this.title}}: {{this.review.rating.value}}/5 </li>
{{/each}}
</ul>
</div>
</body>
</html>
copy successIt is important to note here that the results of the query are accessed via the variable data,
as done on the line 10 with {{#each data}} in the above code.
You can find the files we created up until this point here.
7. How to run Walder
We now have all the files in place to use Walder for the first time. If you do not have Walder installed, you can do so via
npm i -g waldercopy success
You run Walder via
walder -c config.yamlcopy success
You will see this in the output
info 2020-08-26T13:37:03.152Z : Starting static server... info 2020-08-26T13:37:03.153Z : Static server running. info 2020-08-26T13:37:03.154Z : Parsing route /ratings info 2020-08-26T13:37:03.154Z : - Parsing method get info 2020-08-26T13:37:03.209Z : Starting server... info 2020-08-26T13:37:03.212Z : Started listening on port: 3000.copy success
The output is configurable via the -l, --log option.
See walder -h for more information and other options.
Next, open a browser and navigate to http://localhost:3000/ratings.
The result is a list of tv shows together with their ratings:
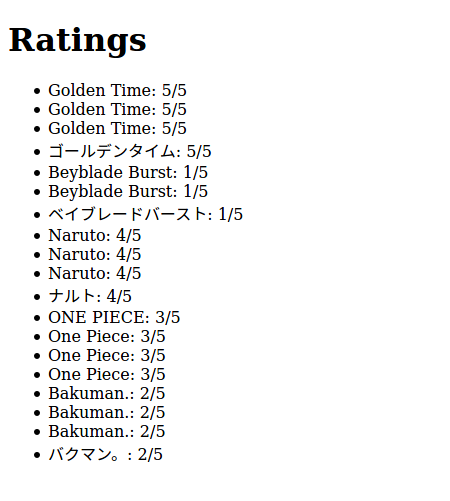
8. How to process query results
When checking the results on http://localhost:3000/ratings
we see that there are duplicate results:
certain tv shows are shown multiple times.
This is due to the fact that tv shows have different titles,
possibly in different languages.
Walder offers the functionality to process the results of a query.
You do this via the x-walder-postprocessing section,
which has a section for every function that needs to be executed on the results.
In our example this is
x-walder-postprocessing:
keepSingleENTitle:
source: utils.js
copy successThis means that we want to use the function keepSingleENTitle which can be found
in the file utils.js.
Walder will look for this file in the folder pipe-modules
relative to the location of the config file.
We do the following steps:
- Create a folder
pipe-modules. - Add a file
utils.jswith the following content:
module.exports = {
keepSingleENTitle: (queryResults) => {
const originalData = queryResults.data;
// Keep only English titles.
const english = /^[A-Za-z0-9 .]*$/;
const showsWithEnglishTitles = originalData.filter(show => english.test(show.title) );
// Filter duplicate shows.
const ids = []
const shows = []
showsWithEnglishTitles.forEach(show => {
// Only add show when the id hasn't been encountered yet.
if (ids.indexOf(show.id) === -1) {
ids.push(show.id);
shows.push(show);
}
});
queryResults.data = shows;
return queryResults;
}
};
copy successThe resulting config file is
openapi: 3.0.2
info:
title: 'Ratings website'
version: 1.0.0
x-walder-datasources:
- https://data.betweenourworlds.org/latest
- https://pieterheyvaert.com/data/example/walder/ratings.ttl
paths:
/ratings:
get:
summary: Returns a list of all tv shows and their ratings.
responses:
200:
description: List of all tv shows and their ratings.
x-walder-input-text/html: ratings.handlebars
x-walder-query:
graphql-query: >
{
id @single
title @single
review @single {
rating @single {
value @single
}
}
}
json-ld-context: >
{
"schema": "http://schema.org/",
"review": "schema:review",
"rating": "schema:reviewRating",
"value": "schema:ratingValue",
"title": "schema:name"
}
x-walder-postprocessing:
keepSingleENTitle:
source: utils.js
copy successIf you run Walder again and browse to http://localhost:3000/ratings
we see every show only once with an English title:

You can find the files we created up until this point here.
9. How to add parameters to paths
The second Web page of our website
lists all tv shows with "x" star ratings at the path /rating/{x},
where "x" is a value between 1 and 5.
The corresponding path entry is
/rating/{value}:
get:
summary: Returns a list of all tv shows with a given rating.
parameters:
- in: path
name: value
required: true
schema:
type: integer
description: Rating of the tv shows.
responses:
200:
description: List of all tv shows with a given rating.
x-walder-input-text/html: selected-rating.handlebars
x-walder-query:
graphql-query: >
{
id @single
title @single
review @single {
rating(value: $value)
}
}
json-ld-context: >
{
"schema": "http://schema.org/",
"review": "schema:review",
"rating": "schema:reviewRating",
"value": "schema:ratingValue",
"title": "schema:name"
}
x-walder-postprocessing:
keepSingleENTitle:
source: utils.js
copy successThe differences with the first path entry are
- the addition of a
parameterssection which contains all information about the supported parameters, and - the use of a parameter value in the GraphQL-LD query.
The parameters section contains an entry for every parameter.
This path entry only has one parameter:
in: path
name: value
required: true
schema:
type: integer
description: Rating of the tv shows.
copy successindefines where the parameter can be found. In this case that is the path.namedefines the name of the parameter. In this case the name isvalue.requireddefines whether a parameter is required or not. In this case the parameter is required.schemadefines the schema of the parameter. In this case we only make us of thetypekey, which states the data type of the parameter. The type isinteger, because a rating is an integer between 1 and 5.descriptioncontains the description of the parameter.
To use the value of the parameter in our query,
we use $value.
That is $ and the name of the parameter.
Our query is
{ id @single title @single review @single { rating(value: $value) } }copy success
rating(value: $value) means that we only want the ratings that have values that match $value.
The view for this path is in the file selected-rating.handlebars with this content:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
</head>
<body>
<h1>TV shows</h1>
<div>
<ul>
{{#each data}}
<li>{{this.title}}</li>
{{/each}}
</ul>
</div>
</body>
</html>
copy successThe only difference with the previous view is that in this one the ratings are not shown, because they are the same for all tv shows on the Web page and determined by the parameter in the path.
Do the following steps to update our files:
- Add the aforementioned path in
config.yaml. - Add the file
selected-rating.handlebarsto the folderviews.
If you run Walder again and
browse to http://localhost:3000/rating/2
we only see one show with a two-star rating:

You can find all files here.
10. Bonus: content negotiation
Besides offering HTML pages,
Walder can also offer RDF and JSON-LD.
This is supported through the use of content negotiation.
You use the Accept header to achieve this.
Let's have a look at the following cURL commands.
curl -H 'accept: text/turtle' http://localhost:3000/rating/2copy success
This command returns all shows with a two-star rating in the Turtle serialization:
<https://betweenourworlds.org/anime/bakuman> <http://schema.org/name> "Bakuman."; <http://schema.org/review> _:b1_b0. _:b1_b0 <http://schema.org/reviewRating> "bc_0_n3-71".copy success
curl -H 'accept: application/ld+json' http://localhost:3000/rating/2copy success
This command returns the same data, but uses JSON-LD instead:
{
"@context": {
"schema":"http://schema.org/",
"review":"schema:review",
"rating":"schema:reviewRating",
"value":"schema:ratingValue",
"title":"schema:name"
},
"@graph":[
{
"title":"Bakuman.",
"review":{
"rating":["bc_0_n3-71"]
},
"@id":"https://betweenourworlds.org/anime/bakuman"
}
]
}
copy successcurl -H 'accept: text/html' http://localhost:3000/rating/2copy success
This command returns the HTML version of the data, which is what is shown in the browser.
11. Wrapping up
Congratulations! You have created your first website using Walder that
- offers two Web pages
- is based on two different, decentralized knowledge graphs
- supports content negotiation to return the data in different formats and serializations.
Nice work! We hope you now feel like you have a decent grasp on how Walder works.
12. More information
You can find more information in the following:
----If you have any questions or remarks, don’t hesitate to contact me via email or via Twitter.