Add content negotiation to website when using NGINX
2019-02-25
Content negotiation
(conneg) is an HTTP mechanism that makes it possible to serve different representations of a resource at the same URI.
This allows agents to specify which representation of a resource they prefer.
For example, on the one hand, when a browser opens http://example.com/house it will ask for an HTML document from the server.
On the other hand, another application that works with XML documents, can request the same resource at http://example.com/house,
but the application will ask for the resource's XML representation.
In this blog post we will explain how you can achieve conneg for your website
when using NGINX.
We want to achieve the following:
- Use NGINX as reverse proxy.
- Serve a static website, which has different documents for the same resource.
- Enable conneg for that website.
First, we have a look at the tools we use. Second, we discuss the setup and configuration. Finally, we show two live examples and summarize this blog post.
Tools
NGINX does not support conneg out of the box. There are tutorials and blog posts available that explain how to achieve some kind of conneg, but they are heavily tied to a specific use case. Thus, they require significant changes to make it work for your use case and are not easily reusable. If NGINX doesn't support conneg, then why not just pick something else. Well, although NGINX lacks this feature, it does work great for the other things such as high performance, caching, acting as a reverse, and so on.
So what do we use to enable conneg?
We use a fork of http-server.
http-sever is "a simple, zero-configuration command-line http server" build using Node.js.
We created a fork that supports conneg.
In more details: the server looks for the correct file depending on the MIME Types in the Accept header.
MIME Types are linked to their corresponding extensions.
For example, when you do a request to http://localhost:8080/test with Accept header text/turtle,
the server looks for the file /test.ttl.
When you do a request to http://localhost:8080/test with Accept header application/n-triples,
the server looks for the file /test.nt.
Accept headers with multiple types,
optionally weighted with a quality value, are also supported.
For example, when you do a request to http://localhost:8080/test with Accept header text/turtle;q=0.5, application/n-triples,
the server looks for the file /test.nt.
Setup
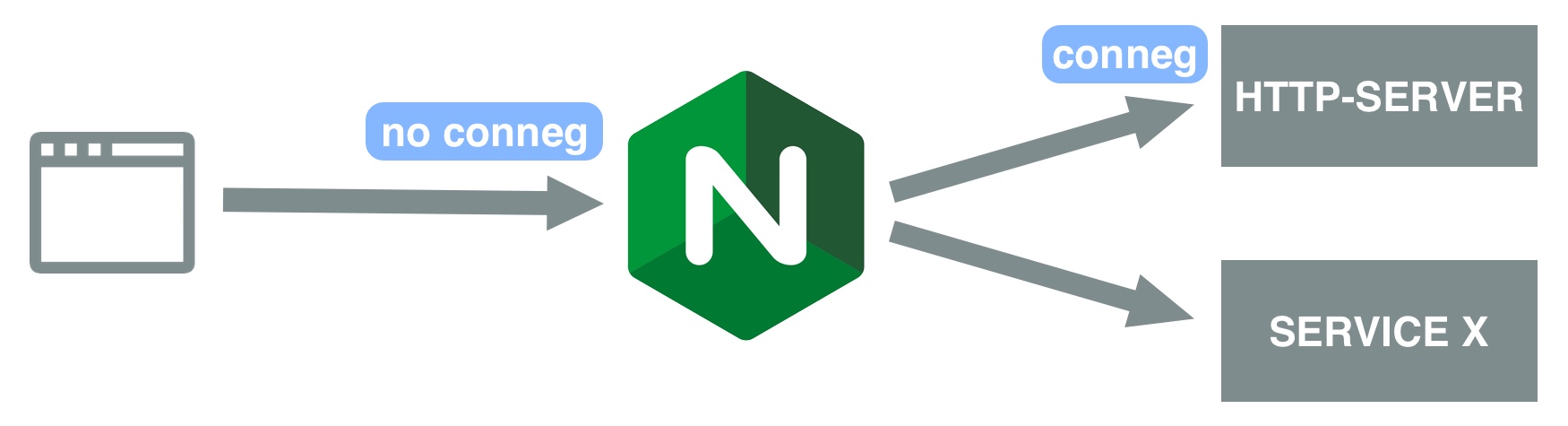
All requests to our website are forwarded to the http-server where conneg is preformed. NGINX is not aware of conneg.
You can find an overview of the different components of our setup in the figure above. We have three services running: NGINX, the http-server, and a service X. The latter service can be anything, and there is no limit to the number of services. All requests are received by NGINX and the ones for our website, for which we want conneg, are redirected to the http-server. NGINX is unaware of any conneg, as all requests are just forwarded to the http-server. Service X is added to show that other services behind NGINX are also unaware of the conneg, as all conneg logic is handled in the http-server. Of course, service X can also support conneg, but that does not influence the (conneg of the) http-server.
Configuration
We need to configure both NGINX and the http-server in order for both to work together. The relevant part of the NGINX config looks as follows:
location / { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_set_header X-NginX-Proxy true; proxy_pass http://127.0.0.1:4000/; proxy_redirect off; }copy success
The most important line is proxy_pass http://127.0.0.1:4000/; where it says that requests are forwarded to the http-server,
which is running on the same server as NGINX and on port 4000.
Of course, you can run it on another server and port.
When you enable caching via NGINX together with conneg,
it is important to add the Accept header to the proxy_cache_key,
for example, via proxy_cache_key "$request_uri $http_accept";.
If you don't do this, then the Accept header is not considered for the cache,
because the default value for proxy_cache_key is $scheme$proxy_host$request_uri.
Note that $http_accept is missing.
As a result, once a cached version of a resource is available,
that cached version is returned regardless of the value of the Accept header in new requests.
The http-server is running on port 4000, with conneg and the automatic addition of trailing slashes enabled, in silent mode.
This is achieved via http-server -p 4000 --conneg --trailing -s where:
-p 4000: use port 4000,--conneg: enable conneg,--trailing: enabled automatic addition of trailing slashes, and-s: enable silent mode.
For more details on the available parameters, we refer to the README.
Examples
The setup described above is already available in the wild: the descriptions of Pieter Heyvaert and the Open Velopark Ontology are available in different representations through conneg.
Describing a person via HTML and RDF
A person's website main goal is to provide information about that person to others. When browsing to that website, an HTML document is downloaded from the server and displayed. However, applications might prefer another representation that is easier for them to process. By offering conneg for a persons's website, applications can decide which representation to request. For example, browsers request an HTML representation to display to users, while Linked Data applications request an RDF representation to easily process the data.
Basic information about Pieter has been made available in both HTML and RDF (serialized in Turtle and RDF/XML) through conneg, using the setup described above.
When you do a GET to https://pieterheyvaert.com/#me without an Accept header,
an HTML document is returned that provides information about Pieter,
such as topics of interest and ongoing work.
Try it out yourself by browsing to https://pieterheyvaert.com/#me or via
curl https://pieterheyvaert.com/#mecopy success
When you do a GET with the Accept header text/turtle,
RDF in Turtle format that describes Pieter is returned.
Try it out yourself via
curl -H 'accept: text/turtle' https://pieterheyvaert.com/#mecopy success
And finally, when you do a GET with the Accept header application/rdf+xml,
RDF in XML format is returned.
Try it out yourself via
curl -H 'accept: application/rdf+xml' https://pieterheyvaert.com/#mecopy success
Explaining an ontology via HTML and RDF
Ontologies provide structured descriptions of domain models. They define the different concepts and elements of a certain domain and describe how they are related to each other. Take for example the Open Velopark Ontology. This ontology provides a description of concepts and properties related to bicycle parkings. This description can be used, for example, by people wanting to know what different types of bike parkings are contemplated in the domain model or by machines to automatically discover and reason over data about bike parkings.
The information contained in the ontology needs to be delivered in the right format for the right audience. For humans using a browser, a HTML representation would be the most appropriate format while for machines, a machine-readable format (e.g., RDF, JSON, XML and so on) would probably be the best fit. This is where conneg comes into play. By exposing different representations of the same resource through its URI, we are saying that anyone and anything can request the information contained in that resource using the format they need (if available of course).
The Velopark Ontology has been made available in both HTML and RDF (serialized in Turtle) through conneg, using the setup described above.
When you do a GET to http://velopark.ilabt.imec.be/openvelopark/vocabulary without an Accept header,
an HTML document is returned that provides information about the ontology.
Try it out yourself by browsing to http://velopark.ilabt.imec.be/openvelopark/vocabulary or via
curl http://velopark.ilabt.imec.be/openvelopark/vocabularycopy success
When you do a GET with the Accept header text/turtle,
RDF in Turtle format that describes the ontology is returned.
Try it out yourself via
curl -H 'accept: text/turtle' http://velopark.ilabt.imec.be/openvelopark/vocabularycopy success
Summary
In this blog post we show that we can add conneg to a website by using NGINX together with the http-server. Both NGINX and the http-server can be easily configured to support this. Different documents corresponding with the different representations for each resource are served by the http-server depending on the Accept header of the request. NGINX and other services running behind it are unaware of conneg.
----If you have any questions or remarks, don’t hesitate to contact me via email or via Twitter.