Solid World February 2019 summary
2019-02-10
On the 6th of February I presented my proof of concept chess game Solid Chess at Solid World. It is a monthly webinar where different themes of Solid are discussed. As a matter of fact, it was the first edition of Solid World. Here is a link to the next one. In this blog post I will summarize what I explained and discussed during my presentation.
Solid Chess
Solid Chess is a chess game based on Solid. It is written in JavaScript, and works in the browser and terminal. There is a live demo and the code is publicly available.
Features
Before I started developing the app, I decided upon three features that had to be included in the app:
- All game data must be stored on the Solid PODs of the players. No central server is used.
- Game updates are sent to the PODs using the notification/inbox mechanism, i.e, Linked Data Notifications.
- All data is materialized using RDF.
Used libraries
The three libraries that I use and that I want to highlight are comunica, query-ldflex, and semantic-chess.
Comunica is a highly modular and flexible meta query engine for the Web. I use it to execute SPARQL queries on the files which I download from the PODs. Besides SPARQL, you can also use GraphQL-LD, which is basically GraphQL for Linked Data, and you can also do federated queries. That means that you can execute a single query over multiple, different data sources, including files, SPARQL endpoints, and TPF servers. So I recommend to have a look at Comunica in case you are dealing with (complex) queries in your app.
Query-ldflex is a library that brings the LDflex language to Solid. LDflex makes is easier for developers to use Linked Data and RDF in their applications, without the need to understand all the technicalities and details of the latter two. This removes the need for SPARQL queries in certain cases. Therefore, I highly recommend to check out this library as it will save you a lot of time writing and executing error-prone SPARQL queries.
Semantic-chess is a library that offers a semantic "wrapper" around chess.js, which is a JavaScript chess engine. I developed this library myself in order to make it easier to work with RDF in the application. It basically has the same methods as chess.js, but it generates RDF when a new game is created, RDF for the notifications to send to the players, and SPARQL UPDATE queries to update an existing game on a POD. The data model used by this library is based on the Chess ontology. Therefore, this library offers one representation of chess games and their players. And, consequently, other libraries or apps not using this library can produce (and consume) different RDF. But more on that in the next section.
Data model
Image that two chess apps are developed by two different companies. Thus, both apps are in the same domain, i.e., the chess domain. The companies decided that their apps store data in RDF on PODs. Nice! We can share data between both apps. Just like that! After playing with app A for a week you want to have a look at app B. But, when you open up the app your previous chess games, which you played with app A, are not shown. Hmmm that is weird. You quickly open up the dev console in your browser and notice that the SPARQL query that is fetching all the game information is not returning anything. Why is that?! Considering that both apps work with RDF, shouldn't the query provide the expected results?
The answer is no. RDF alone does not solve the data interoperability problem. Although different apps can use RDF, they can have a different data model, which can make queries from one app unreusable on the data generated by the other app. How is it possible that different data models are created? Well, two, but there are more, possible reasons are that different apps tackle different problems and that different ontologies are used to model the problem.
Different apps tackle different problems within the same domain. For example, playing a chess game vs. creating a leaderboard of chess players. The game cares about every aspect of the game: the moves, the players, the state of the board, and so on. The leaderboard might care less about the details of game, but more about the details of the players, how many games they've won, and which tournaments they participated in. So the data model contains different types of information, with different levels of detail, which makes the reuse of queries harder.
Different ontologies that describe the same (sub)domain are used. For example, one app uses a chess ontology, while another one uses a board game ontology. This leads to the use of different classes and properties, which makes the reuse of queries harder.
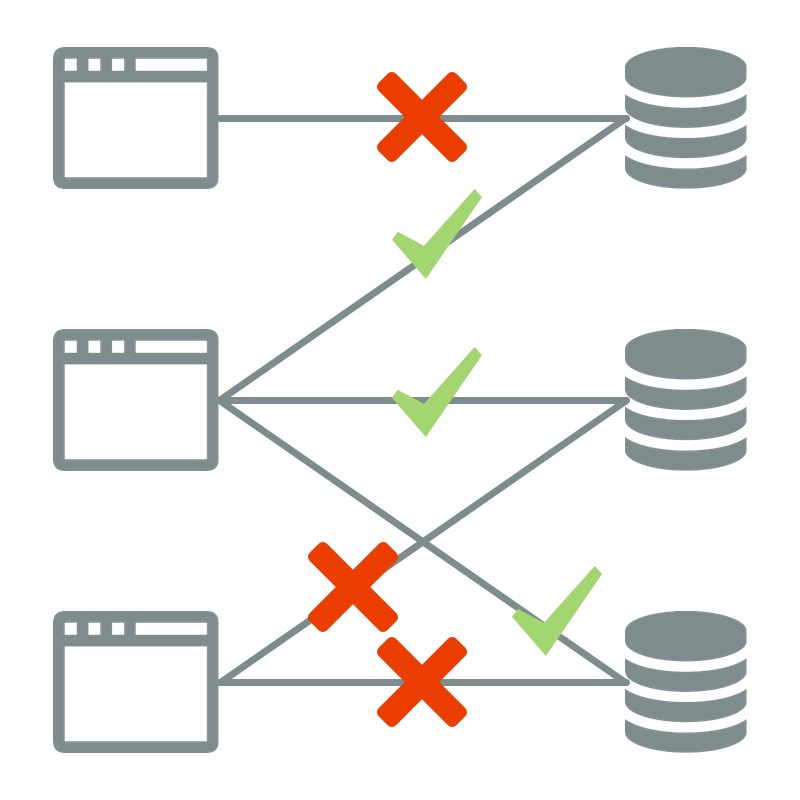
A non-reusable RDF data model leads to isolated apps.
When RDF data models are not designed with the required care, it will lead to isolated apps. One app will be able to work with the PODs of the users and users own their data, but another app will have a hard time using that data, which is not what we want. Therefore, the data model is one of the most important aspects of designing a Solid app.
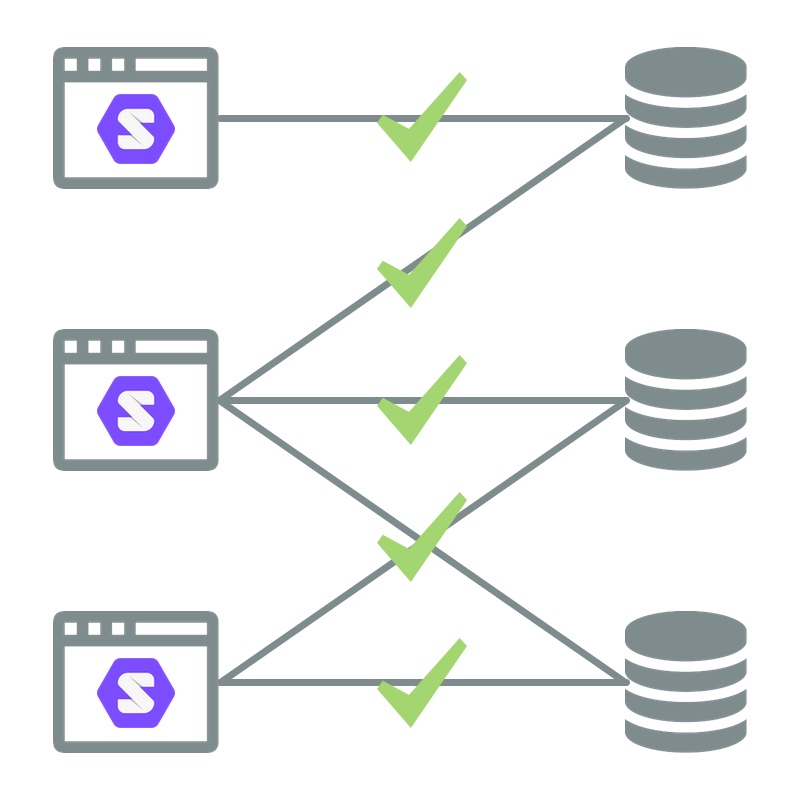
A reusable RDF data model leads to Solid apps.
Here are few practical pointers for when you design your data model:
- Check for existing ontologies, for example, using Linked Open Vocabularies.
- Do not only focus on your use cases. Think bigger. More abstract too.
- Add classes an properties that your app doesn't need,
but that might be useful for other apps.
For example, I can add the class
schema:Eventto a chess game, though I don't use it. But, for example, a calendar app, which works with events, can still show the game.
And, finally, an idea to conclude: what if we define shapes, for example, via SHACL or ShEx, for our apps to express the characteristics of the data that our apps generate and consume? This way we can check how compatible different apps are with each other and different types of RDF data. This has been mentioned too on the Solid Gitter and during the monthly Solid telco. What do you think?
----If you have any questions or remarks, don’t hesitate to contact me via email or via Twitter.